ThinkAutomation powers your business process automation. Automate on-premises and cloud-based business processes to cut costs and save time.
Automate incoming communication channels, monitor databases, react to incoming webhooks, web forms and chat bots. Process documents, attachments, local files and other messages sources.
Parse and extract data from incoming messages and perform business process actions, such as outbound communications, updating on-premises and cloud databases, CRM systems and cloud services, document processing, systems integration and much more.
With ThinkAutomation, you get an open-ended studio to build your automated workflows without volume limitations, and without paying per process, workflow or 'bot'.
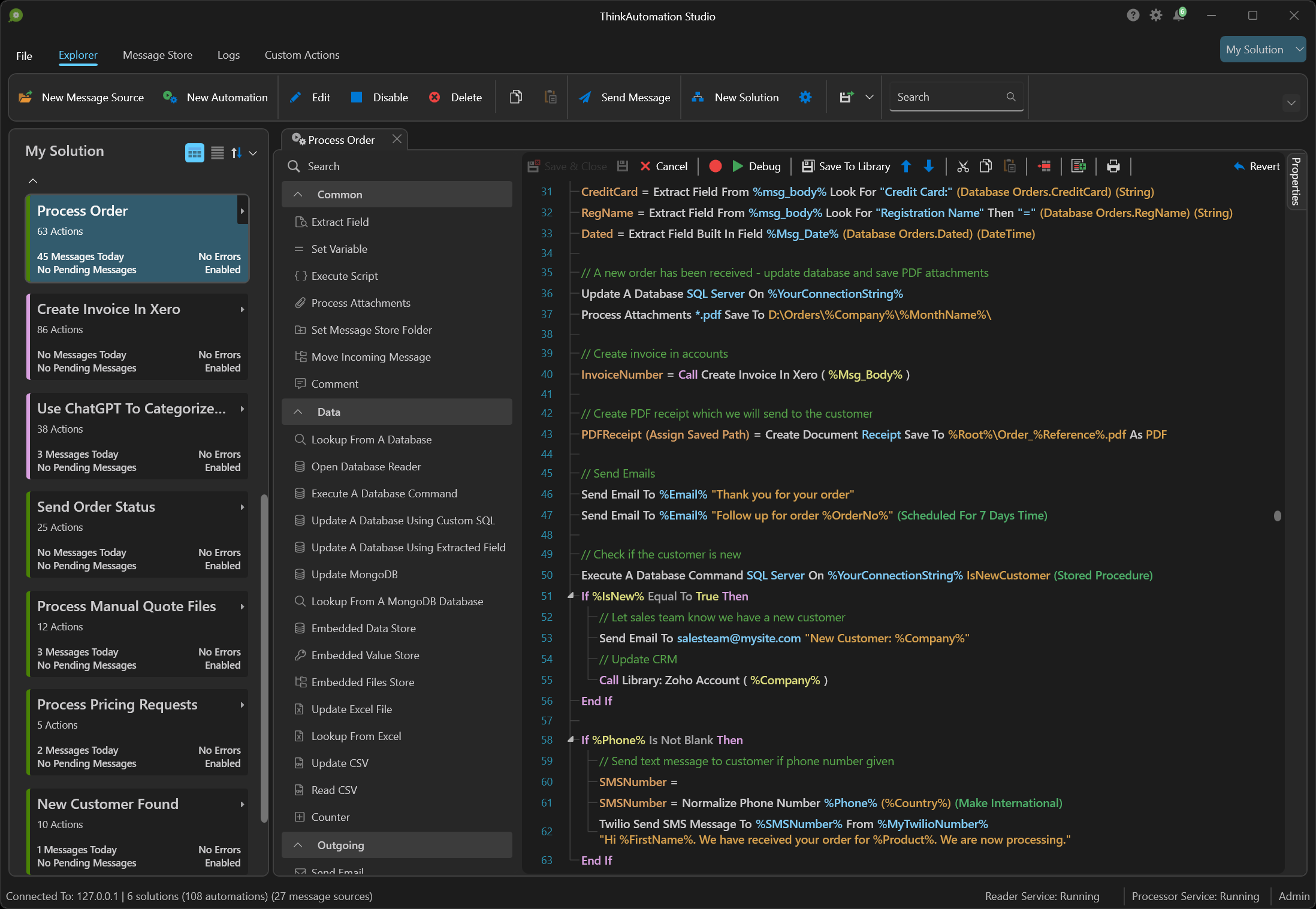
ThinkAutomation is designed to handle any business process - locally and in the cloud. Create simple or complex automations with an easy-to-use, drag-and-drop, low-code workflow designer. You can further extend the capabilities with C# or VB.NET scripting. ThinkAutomation can work in any application, on any scale required.
Automate your way to efficiency with ThinkAutomation.